
在高企的算力、场景、研发壁垒之下,并不是所有企业都适合自研大模型,对于大多数企业而言,需要更经济的参与方式。

前些时候,“天才黑客”George Hotz在接受Latent Space(一家AI技术播客)采访时曾透露,OpenAI的GPT-4其实是一个由8个2200亿参数组成的混合专家模型,核算下来,即为1.76万亿参数。同时,这些模型还经过了针对不同数据、任务分布及推理的训练。
尽管这种说法并没有得到OpenAI官方回应,但随着这一讨论的持续发酵,另外两个话题也随即被推向了舆论的前端。
一个是统治了半导体产业大半个世纪的“摩尔定律”或已走向终结,取而代之的,将是锚定在算力层的“新摩尔定律”;另一个则是暴涨的算力需求,会快速诱发算力焦虑,以及各路玩家对于算力资源的争夺。
尽管眼下大模型风头最盛,但众所周知,大模型对于数据、算力、投入等方面的极高的要求,市场已经逐渐意识到——似乎并不是所有企业都适合自行开发,对于大多数企业而言,或许需要一种“更经济”方式,参与到新生产力时代。
时代呼唤新的数字基础设施服务商。从云入端,数字基础设施服务商应该如何切入、怎么部署,或许,我们可以从6月28日火山引擎大模型发布会上找到一些答案。
让“火箭”再飞一会儿
关于自研大模型的 “ 机会问题 ” ,金沙江创投的朱啸虎与正在进行 GPT创业的傅盛恰好有过一轮交锋。
作为创业者,傅盛认为,大模型催生了很多新的架构在大模型之上的创业机会,但作为投资方的朱啸虎,则认为大模型摧毁了创业。因为模型、算力和数据,到目前阶段已经多数集中于大厂。
这种认知,是朱啸虎在AIGC领域投资多次之后所得出的结论。而在后续回应中,朱啸虎的千言万语则汇成了八个字:场景优先,数据为王。
一位科技领域资深学者也曾表达过同样的观点。在他看来,通用大模型是一项高耗能、高投入的“长期事业”,无论是出于能力方面的考虑,还是出于必须性方面的考虑,自研大模型并非适用于所有企业。
对于绝大多数企业(特别是中小企业)而言,想要搭乘大模型的“快车”实现将本增效,最理性的选择,或是借助一些外部数字基础设备服务商的力量,有针对性地解决场景应用问题。
对此,火山引擎总裁谭待则认为,在模型应用端,面对多模型生态和企业1+N应用模式,同样需要提供更好的产品和方案,解决这里面计算、安全、成本等通用问题。让交易成本足够低,让替代成本足够低,这样才能不断降低大模型的使用门槛,让众多企业可以更加高效的应用大模型技术。
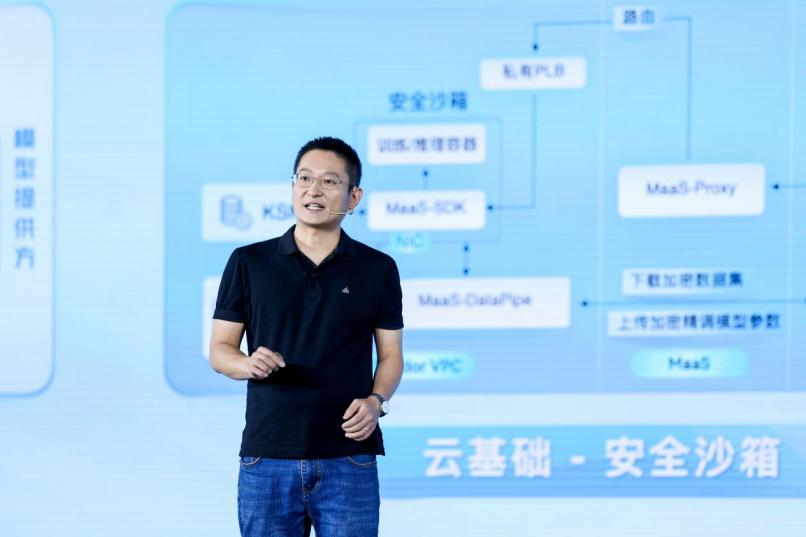
只不过,随着不同产业、不同企业对大模型需求的暴涨,技术密度、网络带宽、存储需求等等,都呈现出几何级增长,算力的巨量消耗显然是一个无法忽视的问题。火山引擎算法负责人吴迪将其划分为“三级火箭”的体系——
第一级的大模型供应商和研究机构,负责为全行业提供具备竞争力的基座模型和垂直模型;第二级技术积累深厚的公司,在保留自研模型的同时,也会调用其他厂商的模型落地至不同场景;第三级的各行业大模型应用商,则会把大模型能力深入到生活的各个领域。
大模型一旦进入大规模应用阶段,用来调试和推理的算力消耗,将会迅速超过了模型预训练所需的部分。按照吴迪的预测,到2024年秋天之后,以推理为主的大模型算力消耗,将超过预训练消耗的60%,并且在2025年的某个时刻,超越预训练算力消耗。
在此基础上,对于在应用层跃跃欲试的大模型应用企业来说,与其绑定某一家厂商的大模型,同样的成本如果拿来调用多个精调之后的垂类模型,效果可能会更好。原因无他,性价比是选用模型的核心因素——
不同模型在不同的场景下,效果是各擅胜场。一个经过良好精调的中小规格模型,在特定工作上的表现可能不亚于通用的、巨大的基座模型,而推理成本可以降低到原来的十分之一。
在这种综合认知下,与其他大模型厂商所走的路径有所不同,火山引擎的切入方式并非是从头自研,而是发布大模型服务平台“火山方舟”,面向企业提供模型精调、评测、推理等全方位的平台服务(MaaS,即Model-as-a-Service)。
从这种结构来看,“火山方舟”正试图打造一家初具规模的“AI商店”,某种意义上,这或许也是大模型行业发展的某种必然。
选模型,也是一门技术活
对于大部分企业而言,大模型的需求固然已经出现,但在 “ 万模竞发 ” 大背景下,应该如何选择适配自己真实需求的大模型,同样也是一道难题。
所谓“难”,主要体现在两个方面——
其一,与判别式AI相比,生成式AI暂时没有行业标准可供参考,企业如果按传统的销售逻辑一家家寻找和调用,成本显然难以控制。
其二,企业使用大模型,数据泄露是首要担心的问题。谭待提到,与此前的深度学习实践不同,模型提供方和使用方,现在很可能已经出现了分离;特别是,如果到了私有化部署的阶段,不仅作为使用方的企业要承担更高成本,作为模型生产方也会担心自己的知识资产。

谭待的担心显然不是空穴来风,因为在此之前,与大模型相关的企业数据泄露案例就已经有所浮现。
早在今年初,三星公司在“全面拥抱”ChatGPT之后,在20天内就发生了3起机密外泄事件,其中两次和半导体设备有关,1次和内部会议有关。这让三星半导体的核心机密,通过ChatGPT泄露。
究其原因,三星员工直接将企业机密信息以提问的方式输入到ChatGPT中,会导致相关内容进入学习数据库,从而可能泄漏给更多人。在“数据防火墙”构建尚未完善时,贸然在公司业务中使用大模型的风险,不言而喻。
正因如此,火山方舟已经上线了基于安全沙箱的大模型安全互信计算架构。根据吴迪的介绍,该方案采用了计算隔离、存储隔离、网络隔离和流量审计等手段,以确保模型的机密性、完整性和可用性。
此外,对于如何选择适合企业的大模型,谭待给出了自己一些想法,他认为,企业首先需要明确自己的需求,并基于需求场景,制定可量化的评估指标。
这意味着,模型的能力主要分为逻辑推理、文本生成和风险控制等很多种,各种能力的不同侧重导致了成本分布的不同。企业根据自己的需求,需要对这些能力进行全方位测评,选择性价比最合适的。
做好提示工程同样重要。这里不仅包括任务内容、相关信息和说明,同时还要给到样本与示例,同时,再通过“step by step”这样cot的方式,进一步加强模型的性能;
插件与工具链的对接,同样也不可或缺。因为在模型与提示工程完备之后,合适的插件与工具是激活模型生产力不可或缺的棋子。当这些工具在合适的场景下加以利用,能更好满足企业的相关需求。
大模型商业化的“火山样本”
无论是数据安全还是模型精调,都是企业在构建、训练大模型过程中不可或缺的环节。这也是火山方舟所能提供的重要价值之一。
在接受媒体采访时,谭待更是重申了火山方舟的平台属性。他认为,基于此前的多模型行业判断,所以需要平台提供对应的多模型服务能力,让企业可以更方便使用对应模型。
回到火山方舟,在目前阶段,同样也并不会下场做自研模型,而是侧重于为企业提供安全、低成本的服务平台。
在发布会现场,陆玖商业评论了解到,通过火山方舟平台,企业可以用统一的工作流对接多家大模型。
如果简单翻译则是,在同一个“选模型”流程下,企业可以同时对多个模型同时进行调试和能力评测,甚至在不同场景下,还可以灵活切换不同的模型,实现最优的模型组合。这也是火山引擎一直强调多模型“高性价比”的意义所在。
值得注意的是,火山方舟上线的可用模型数量在7个左右。这也是火山方舟“精品策略”的体现。如智谱AI旗下的千亿基座认知模型ChatGLM,通过与火山方舟的精调能力和综合解决方案相结合,已经成功解决了千亿模型训练的稳定性、性能优化等挑战。
在MMLU、C-Eval等中英文权威榜单中表现优异的baichuan-7B同样也是如此,入驻火山方舟之后,企业用户的大模型接入门槛和使用成本出现了显著下降,对于更多企业而言,以较低成本获取专业服务,自此成了现实。
尽管大模型方兴未艾,但业内已基本形成了这样一种共识:大模型真正的价值体现,还是落脚在能与企业的实际需求相结合,并最终在产业层面激活生产力。
无论是“多模型”火山方舟,还是其他科技企业发布的大模型产品,对于这些数字基础设施服务上来说,接下来要做的事情还有:AI基础设施的创新突破,产业链的深度构造,行业的持续下沉,以及开发者生态的孕育等等。
大模型时代,数智世界的多面体将会被进一步打开。









 加载中,请稍侯......
加载中,请稍侯......